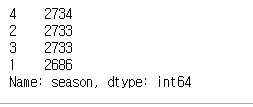
기본 함수들 - unique() : 데이터의 고유 값들이 어떤 것이 있는지 확인 - nunique() : 고유한 값들의 갯수 - value_counts() : 고유 값별 데이터의 수 df_bike.season.value_counts() normalize 및 정렬(ascending) 옵션이 있다. df_bike.season.value_counts(normalize=True) df_bike.season.value_counts(normalize=True).round(2) 변수간 관계 : crosstab pd.crosstab(df_bike['weather'], df_bike['season']) 공통된 데이터로 그룹화 : groupby 예제 : cut을 기준으로 그룹화 한 후, price에 대한 min, max,..