머신 러닝(Machine Learning)
- 기계학습이라고도 하며 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야
- 추정 및 추론에 중점을 두는 통계와는 달리 주로 예측에 초점을 맞추고 있음
- 주어진 기반으로 학습을 하여 비교적 일반화된 수식 또는 규칙이 담긴 모델을 생성하고 교정함
- 생성한 모델을 각 알고리즘의 고유한 평가지표 또는 범용 평가지표를 활용하여 평가함
머신러닝의 종류
1) 지도학습(Supervised Leaning) (or 교사 학습 / or 감독학습)
- 학습 데이터 안에 입력값에 대한 출력값이 함께 제시됨
- 알고리즘은 입력값과 출력값 사이의 관계를 가장 잘 설명할 수 있는 '모델'을 찾음
- 이 '모델'을 사용하여 새로운 입력값에 대한 예측 수행
- 출력값이 수치형인 회귀와 범주형(글자형)인 분류 문제로 나누어 짐
=> 대표 지도학습 알고리즘
1) KNN(K-Nearest Neighbors) : 회귀/분류
2) 선형 회귀(Linear Regression) : 회귀
3) 로지스틱 회귀(Logistic Regression) : 분류
4) 의사결정 나무(Decision Tree) : 회귀/분류
5) 랜덤 포레스트(Random Forest) : 회귀/분류
2) 비지도학습(Unsupervised Learning) *타겟값이 없음/출력값이 없음
- 학습 데이터 안에 출력값이 없음
- 알고리즘은 학습 데이터의 특징만을 활용하여 목표한 결과를 산출
- 적절한 군집을 찾거나, 변수의 복잡성을 낮추기 위한 차원 축소 등이 비지도 학습에 포함됨
- GAN(Generative Adversarial Nets) 등과 같은 새로운 기법이 등장하고 있음.
=> 대표 비지도학습 알고리즘
1) 군집분석 :k-means, 계층적 군집분석
2) 차원축소 : 주성분 분석, t-SNE
3) 추천시스템 : 연관성분석, 이클렛(Eclat)
3) 강화학습(Reinforcement Learning)
- 구체적인 행동에 대한 지시가 없이 목표만 주어짐
- 현재 상태에 대한 최선의 액션을 보상(Reward)에 의해 스스로 찾아 학습하게 하는 방법
- 학습한 내용은 최고의 결과를 얻기 위한 전략으로 활용됨
- 데이터에서 보지 못한 내용에도 적응하여 반복하면서 더 좋은 결과를 얻을 수 있음.
4) Semi-supervised Learning
- 모든 데이터에 항상 레이블을 달아 줄 수 있는 것이 아닌 현실을 고려한 접근법
- 레이블이 달려있는 데이터와 레이블이 달려있지 않은 데이터를 동시에 사용하여 더 좋은 모델을 만들고자 함.
- 항상 최선의 성능이 발휘되는 것은 아니나, 군집 형태에 가까운 경우 좋은 결과를 나타냄.
5) Transfer Learning
- 기존의 학습 방법들은 학습에 사용한 데이터와 이후 분석을 하려는 데이터가 같은 분포를 가지고 있다는 가정을 바탕으로 함
- 새로운 문제를 해결하고자 할 때 기존 학습된 모델을 이용하여 새로운 모델을 만드는 방법
- 이미 잘 훈련된 모델이 있고, 해결하고자 하는 문제가 유사성이 있을 경우, 학습 데이터가 부족한 경우 등에 사용
- 기존 pre-trained model을 미세 조정하여 사용하는 학습 방법이 대표적
머신러닝 Workflow
1) Collect data : 유용한 데이터를 최대한 많이 확보하고 하나의 데이터 세트로 통합
2) Prepare data : 결측값, 이상값, 기타 데이터 문제를 적절하게 처리하여 사용 가능한 상태로 준비
* Sampling 방법은 적절한가?
3) Split data : 데이터 세트를 학습용과 평가용 세트로 분리
* 적절한 테스트를 위한 데이터 분할 방법은?
4) Train a model : 이력 데이터의 일부를 활용하여 알고리즘이 데이터 내의 패턴을 잘 찾아 주는지 확인
* 어떤 모델을 사용하지? 어떤 변수를 사용하지?
5) Test and validate a model : 학습 후 모델의 성능을 평가용 데이터 세트로 확인하여 예측 성능을 파악
* 충분한 예측력을 가진 모델인가?
6) Deploy a model : 모델을 의사결정 시스템에 탑재 / 적용
7) Iterate : 새로운 데이터를 확보하고 점증적으로 모델 개선
머신러닝 기본 용어 정리
- 종속 변수 : 결과값이 있으며 추론(예측 또는 분류) 대상이 되는 변수
- 독립 변수 : 결과값을 산출하기 위한 입력값이 있는 변수
- 모델 : 어떤 현상을 설명하기 위한 수식 또는 규칙
- 모델 튜닝 : 모델의 성능 향상이나 해석을 위해 취하는 일련의 조치
- 하이퍼파라미터(hyperparameter) :어떤 것을 조정하기 위한 설정값
- 학습 데이터셋(train dataset) : 모델의 학습에 사용되는 데이터셋
- 검증 데이터셋(validation dataset) : 모델의 최종 평가 이전에 학습 상태를 점검하기 위해 사용되는 데이터셋
- 평가 데이터셋(Test dataset) : 모델의 최종 평가에 사용되는 데이터셋
- 과적합(Overfitting) : 모델이 학습 데이터에 과하게 맞춰진 상태이며 신규 데이터 기반 추론시 저성능 야기
- 과소적합(Underfitting) : 모델이 학습 데이터에 대충 맞춰진 상태이며 전반적으로 추론 결과가 좋지 않음
편향-분산 균형(Bias-Variance Tradeoff) *Trade-off
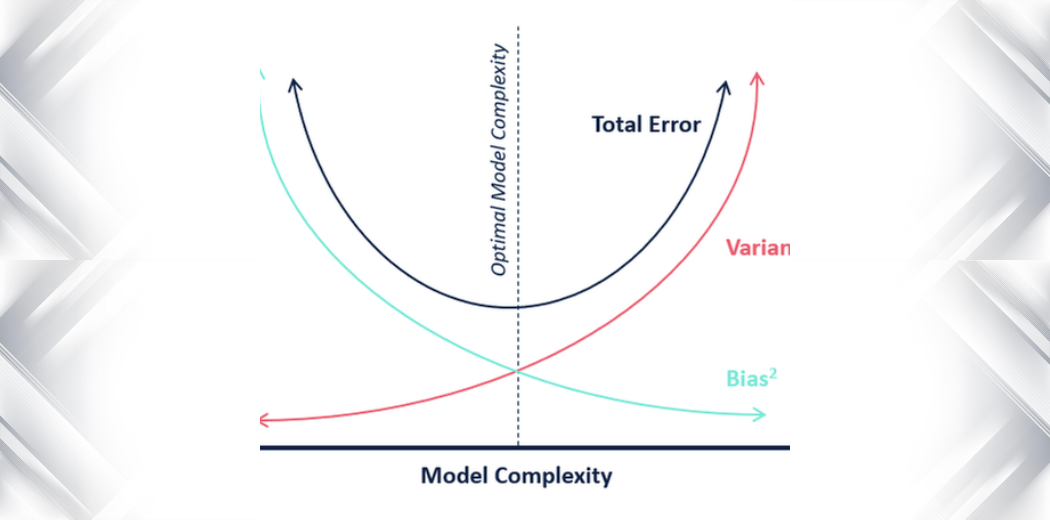
- 편향(Bias) : 지나치게 단순한 모델로 발생되는 오차, 큰 편향은 과소적합(Under fitting)
- 분산(Variance) : 지나치게 복잡한 모델로 발생된느 오차, 큰 편향은 과대적합(Over fitting)
- 편향과 분산을 둘 다 극단적으로 줄이기 어렵기에 타협점을 찾아야 한다.
모델 평가 기법
1) Holdout Test
- 모델의 과적합을 막기 위한 방법으로 주어진 데이터를 두 개 이상으로 나누어 학습 및 평가
- 두 개로 나누는 경우는 훈련(train)/평가(test)세트로 분할하며 일반적으로 7:3 or 8:2로 분할
* 분할 비율은 정답이 없음
- 세개로 나누는 경우는 훈련(train)/검증(validation)/평가(test) 세트로 분할하며 일반적으로 5:3:2로 나눔.
2) 교차검증(CV, Cross Validation)
- k-fold Cross Validation이라고도 함
- 모델의 평균적인 성능을 가늠하기 위해 holdout test를 데이터를 바꿔가며 여러번 실시하는 것
- 데이터를 10개로 분할하여 교차 검증하는 경우 10-fold CV라고 함
* 일반적으로 데이터 분할 시 중복되는 데이터가 없도록 비복원 추출 실시
*Fold개수가 늘어나면 교차 검증 시간이 늘어남
3) 일반적인 모델 선택 과정
- 여러 모델을 대상으로 Cross Validation 수행
- 가장 좋은 결과를 낳은 하나 혹은 소수의 모델 선택
- 학습 데이터를 모두 사용하여 모델 생성
- 분리해 놓은 평가 데이터로 모델 평가
4) 평가지표 - 회귀모델
* 회귀(regression)란, 독립 변수와 종속 변수 간의 관계를 나타내는 모델링 기법, 독립 변수(x)와 종속 변수(y) 간의 상관 관계를 파악하여 종속 변수를 예측하는 모델을 만드는 것을 의미한다. 회귀 모델은 주로 수치형 데이터를 다루며, 주어진 입력 변수에 따라 출력 변수를 예측하는 데 사용된다. 회귀 모델링의 목적은 종속 변수의 값을 최대한 정확하게 예측하는 것!
- 수치형 변수의 평가는 관측값(actual value)과 예측값(predicted value)의 오차를 기반으로 한다.
- 오차를 기반으로 하는 평가는 값이 작을 수록 좋다. *오차를 줄일 수록 성능은 좋다.
- RMSE, MAPE가 많이 사용되는 편이며 특히 MAPE는 백분율로 표기되어 해석에 용이하다.
- MSE는 오차를 제곱하기에 상대적으로 RMSE와 MAE보다 값이 크다.
- MAPE는 특성상 실제값(y)에 0이 있는 경우 문제(발산)가 발생할 수 있다.
*Error : 오차
| MSE(Mean Squared Error) - >오차를 스퀘어드 -> mean(평균) 냄 |
 |
| RMSE(Root Mean Squared Error) ->MSE에 Root씌움 |
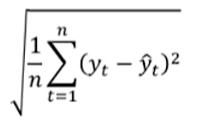 |
| MAE(Mean Absolute Error) -> 'Absolute' 제곱이 아니라 절대값으로. |
 |
| MAPE(Mean Absolute Percentage Error) ->P:Percentage 이니까 100곱함 |
 |
* 결정계수*coefficient of determination : 회귀모델이 주어진 자료에 얼마나 적합한지를 평가하는 지표
- 종속 변수의 변동량과 예측값의 변동량을 비교하는 지표
- 기본적으로 값 범위는 0~1이며, 예측량이 매우 좋지 않은 경우(모델 성능이 낮은 경우) 음수가 산출될 수 있음
5) 평가지표 - 분류모델
- 범주형 변수의 평가는 정분류와 오분류 결과를 기반으로 한다.
- Accuracy, Precision, Recall, F1 score는 1에 가까울 수록 좋다(최소값은 0)
- Accuracy를 가장 먼저 확인하지만 분석 목표에 따라 Precision/Recall/F1 Score를 추가로 확인
https://huiyu.tistory.com/entry/데이터분석-준-전문가ADsP-3과목-데이터-분석-오분류표를-활용한-평가지표
데이터분석 준 전문가(ADsP) 3과목 : 데이터 분석-오분류표를 활용한 평가지표
*오분류표를 활용한 평가 지표 - 정밀도(Precision) : 예측값이 True인 것에 대해 실제값이 True인 지표 - 재현율, 민감도(Recall, Sensitivity) : 실제값이 True인 것에 대해 예측값이 True인 지표 - F1 : 데이터
huiyu.tistory.com
* Confusion Matrix(혼동행렬)은 실제와 예측의 정/오 분류 결과를 표로 표기한 것
'Software Development > Data Science' 카테고리의 다른 글
| 머신러닝 지도학습 - KNN알고리즘 (0) | 2023.04.07 |
|---|---|
| 머신러닝 지도학습 - 의사결정나무(Decision Tree) (0) | 2023.04.06 |
| 주요확률분표 : 이산,연속,균등,이항,포아송,지수 (0) | 2023.04.04 |
| 통계 : 확률 & 베이즈 정리 (0) | 2023.04.03 |
| 통계분석 : 위치 & 변이 통계량 (0) | 2023.04.02 |