기본 함수들
- unique() : 데이터의 고유 값들이 어떤 것이 있는지 확인
- nunique() : 고유한 값들의 갯수
- value_counts() : 고유 값별 데이터의 수
df_bike.season.value_counts()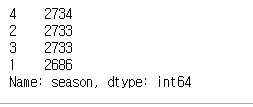
normalize 및 정렬(ascending) 옵션이 있다.
df_bike.season.value_counts(normalize=True)
df_bike.season.value_counts(normalize=True).round(2)
변수간 관계 : crosstab
pd.crosstab(df_bike['weather'], df_bike['season'])
공통된 데이터로 그룹화 : groupby
예제 : cut을 기준으로 그룹화 한 후, price에 대한 min, max,mean,median을 구한 후 median 기준 오름차순 정렬
df_diamond = pd.read_csv('diamonds.csv')
df_diamond.head(3)
df_dia_min = df_diamond.groupby('cut')['price'].agg(['min','max','mean','median']).sort_values(by='median')
df_dia_min날짜 데이터 처리
info()로 날짜 데이터가 object라면, to_datetime()사용
df_bike['datetime'] = pd.to_datetime(df_bike['datetime']) #시간값 바꾸기
df_bike.info()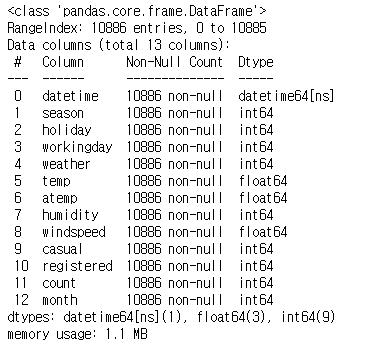
dt를 통해 접근, dt.month 등을 통해 데이터 확인 가능
df_bike['month'] = df_bike['datetime'].dt.month
df_bike이 후 월별 합계 계산
df_bike.groupby('month')['count'].sum()
df_bike
포함한 글자 검색 : contains
>> 여러 글자가 포함되었다면 |를 사용하면 된다.
df_krx.loc[df_krx['지수명'].str.contains('KRX 300|KRX 자동차'), '지수명'].unique()isin을 사용해도된다, 다만 isin은 포함이 완전 일치한 데이터를 가져오는 함수
df_diamond.loc[df_diamond['cut'].isin(['Good','Very Good']), 'cut'].unique()
컬럼을 행으로 보내기 : melt
df_weather = pd.read_csv('weather.csv')
df_weather.head()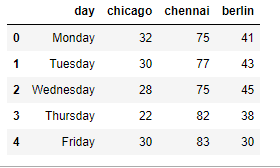
berilin,chicago의 일별 날씨 흐름을 차트로 표현 ->melt 함수
df_weather_melt = df_weather.melt(id_vars='day', value_name='temp')
df_weather_melt
데이터 병합 : concat
df1, df2 = df_weather[:3], df_weather[3:]
display(df1, df2)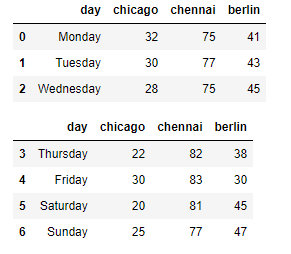
아래로 합치기, axis=0
pd.concat([df1, df2], axis=0)
옆으로 합치기, axis=1
df3, df4 = df_weather[['day','chicago']], df_weather[['chennai','berlin']]
display(df3, df4)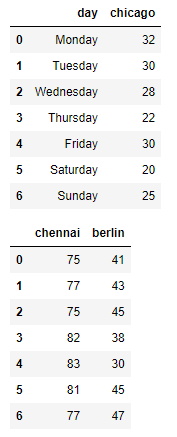
pd.concat([df3, df4], axis=1)
테이블 합치기 : merge
d1 = {'Name': ['장준규', '홍길동', '운영자'], 'Country': ['India', 'India', 'USA'],
'Role': ['CEO', 'CTO', 'CTO']}
df1 = pd.DataFrame(d1, index = ['A1', 'B1','A3'])
df1
df2 = pd.DataFrame({'ID': ['A1', 'A2', 'A3', 'A4'], 'Security_Level': ['VIP1', 'VIP2', 'VIP2','VIP3']})
df2
df3 = pd.merge(df1,df2, how='left', left_index=True, right_on='ID')
df3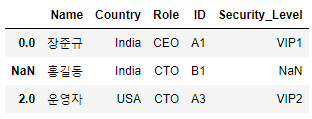
select_dtypes : table에서 자료형에 따른 데이터 선택
col_cate=X_train.select_dtypes(exclude='number').columns
col_catecol_cate = X_train.select_dtypes(include = 'object').columnscol_num = X_train.select_dtypes(include = 'number').columns
728x90
반응형
'개발 > Data Science' 카테고리의 다른 글
| python 함수 소소한 메모 (0) | 2023.04.12 |
|---|---|
| Python - lambda & 정규표현식 기초 (0) | 2023.04.11 |
| 파이썬 Data Science 기초 - DataFrame index (2) | 2023.04.08 |
| 머신러닝 지도학습 - KNN알고리즘 (0) | 2023.04.07 |
| 머신러닝 지도학습 - 의사결정나무(Decision Tree) (0) | 2023.04.06 |