말그대로 그냥 한번 Python에 OpenPose를 붙여서 포즈검출해보기.
언젠가 한번 해보고 싶단 생각을 했었는데 설연휴 시간이 많아 한번 해보기.
아래와 같이 확인해 볼 수 있다.

1. VSCode 기반 Python 환경 빌드환경을 구축하여 Hello Python출력.
https://www.codingfactory.net/11337
Python / Visual Studio Code 개발 환경 만들기
파이썬 개발을 위한 도구는 여러 가지가 있습니다. Visual Studio Code도 그 중 하나입니다. VS Code에 Python 확장 기능을 설치하고, Hello World를 출력해보겠습니다. 확장 기능 설치 Visual Studio Code를 설치
www.codingfactory.net
- debug configuration is invalid 오류가 나오면 아래와 같이 해결.
[vscode] 오류 해결 The Python path in your debug configuration is invalid.
금요일까지만 해도 잘 되던 python 빌드가 갑자기 이렇게 안되었다. 이런 경우에는 다음과 같이 해결하면 된다.ctrl + shift + p 를 누르면다음과 같은 화면이 나온다. 여기서 Python: Select Interpreter를 입
velog.io
만약 리스트에 파이썬이 안나오면다면 직접 파이썬 설치 경로를 설정해주면 된다.
-> C:\Users\[유저이름]\AppData\Local\Programs\Python\Python310\Scripts
2. pip install opencv for python
터미널에서 pip를 이용해서 opencv를 먼저 설치한다.
- 만약 python을 설치했는데 명령어를 못찾는다고 한다면, 시스템 환경변수에 아래 경로를 추가한다.
C:\Users\[유저이름]\AppData\Local\Programs\Python\Python310\Scripts
https://shlee0882.tistory.com/269
window10 cmd에서 pip명령어 사용하기
1. 파이썬 설치 2. 파이썬 환경변수 추가해주기 C:\Users\sanghyun\AppData\Local\Programs\Python\Python38-32\Scripts 3. 관리자권한으로 cmd 다시켜기 4. pip 명령어 사용해보기 이제 pip 명령어를 이용해..
shlee0882.tistory.com
3. Python + OpenPose로 포즈 검출하기
1) OpenPose 다운로드
* OpenPose는 인간 자세 예측(Human Pose Estimation)으로 카메라 한대로 사람의 몸, 얼굴, 손가락 마디를 정확하게 예측할 수 있다. 이미 훈련된 Pose Estimation 모델에 원하는 이미지를 넣어 KeyPoint(관절 포인트)를 검출한 결과를 얻을 수 있다. 딥러닝 합성곱 신경망을 기반하여 영상 및 사진으로만 사람의 몸, 손, 얼굴의 특징점을 추출할 수 있다. 추출한 특징점(관절)을 추정 후 그 위치를 이어 스켈레톤을 형성한다.
https://github.com/CMU-Perceptual-Computing-Lab/openpose
GitHub - CMU-Perceptual-Computing-Lab/openpose: OpenPose: Real-time multi-person keypoint detection library for body, face, hand
OpenPose: Real-time multi-person keypoint detection library for body, face, hands, and foot estimation - GitHub - CMU-Perceptual-Computing-Lab/openpose: OpenPose: Real-time multi-person keypoint de...
github.com
- 코드를 다운로드 받은 후 압축해제
- 경로의 models 폴더 안 getModels.bat파일 실행하여 모델을 다운로드한다.(리눅스 : getModels.sh)
- 생성된 여러 파일 중 pose/mpi 경로 아래 파일 두개를 python의 적절한 위치해 복사해준다.
1) pose_deploy_linevec_faster_4_stages.prototxt
2) pose_iter_160000.caffemodel
-> MPII Human Pose Dataset에서 학습된 관절 검출 모델 사용. MPII 데이터 셋은 관절 부위가 라벨링된 25000장의 이미지를 제공한다.
2) python 소스코드 입력하기 (코칸리's 코오딩 님 코드), 이미지와 파일 경로를 수정합니다.
import cv2
# MPII에서 각 파트 번호, 선으로 연결될 POSE_PAIRS
BODY_PARTS = { "Head": 0, "Neck": 1, "RShoulder": 2, "RElbow": 3, "RWrist": 4,
"LShoulder": 5, "LElbow": 6, "LWrist": 7, "RHip": 8, "RKnee": 9,
"RAnkle": 10, "LHip": 11, "LKnee": 12, "LAnkle": 13, "Chest": 14,
"Background": 15 }
POSE_PAIRS = [ ["Head", "Neck"], ["Neck", "RShoulder"], ["RShoulder", "RElbow"],
["RElbow", "RWrist"], ["Neck", "LShoulder"], ["LShoulder", "LElbow"],
["LElbow", "LWrist"], ["Neck", "Chest"], ["Chest", "RHip"], ["RHip", "RKnee"],
["RKnee", "RAnkle"], ["Chest", "LHip"], ["LHip", "LKnee"], ["LKnee", "LAnkle"] ]
# 각 파일 path
protoFile = "pose_deploy_linevec_faster_4_stages.prototxt"
weightsFile = "pose_iter_160000.caffemodel"
# 위의 path에 있는 network 불러오기
net = cv2.dnn.readNetFromCaffe(protoFile, weightsFile)
# 이미지 읽어오기
image = cv2.imread("img2.png")
# frame.shape = 불러온 이미지에서 height, width, color 받아옴
imageHeight, imageWidth, _ = image.shape
# network에 넣기위해 전처리
inpBlob = cv2.dnn.blobFromImage(image, 1.0 / 255, (imageWidth, imageHeight), (0, 0, 0), swapRB=False, crop=False)
# network에 넣어주기
net.setInput(inpBlob)
# 결과 받아오기
output = net.forward()
# output.shape[0] = 이미지 ID, [1] = 출력 맵의 높이, [2] = 너비
H = output.shape[2]
W = output.shape[3]
print("이미지 ID : ", len(output[0]), ", H : ", output.shape[2], ", W : ",output.shape[3]) # 이미지 ID
# 키포인트 검출시 이미지에 그려줌
points = []
for i in range(0,15):
# 해당 신체부위 신뢰도 얻음.
probMap = output[0, i, :, :]
# global 최대값 찾기
minVal, prob, minLoc, point = cv2.minMaxLoc(probMap)
# 원래 이미지에 맞게 점 위치 변경
x = (imageWidth * point[0]) / W
y = (imageHeight * point[1]) / H
# 키포인트 검출한 결과가 0.1보다 크면(검출한곳이 위 BODY_PARTS랑 맞는 부위면) points에 추가, 검출했는데 부위가 없으면 None으로
if prob > 0.1 :
cv2.circle(image, (int(x), int(y)), 3, (0, 255, 255), thickness=-1, lineType=cv2.FILLED) # circle(그릴곳, 원의 중심, 반지름, 색)
cv2.putText(image, "{}".format(i), (int(x), int(y)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1, lineType=cv2.LINE_AA)
points.append((int(x), int(y)))
else :
points.append(None)
cv2.imshow("Output-Keypoints",image)
cv2.waitKey(0)
# 이미지 복사
imageCopy = image
# 각 POSE_PAIRS별로 선 그어줌 (머리 - 목, 목 - 왼쪽어깨, ...)
for pair in POSE_PAIRS:
partA = pair[0] # Head
partA = BODY_PARTS[partA] # 0
partB = pair[1] # Neck
partB = BODY_PARTS[partB] # 1
#print(partA," 와 ", partB, " 연결\n")
if points[partA] and points[partB]:
cv2.line(imageCopy, points[partA], points[partB], (0, 255, 0), 2)
cv2.imshow("Output-Keypoints",imageCopy)
cv2.waitKey(0)
cv2.destroyAllWindows() 아래 두 페이지를 참고했습니다.
https://bskyvision.com/1164
[python+openpose] openpose 라이브러리를 사용해서 관절 포인트 검출하기 (window 10 환경)
오늘은 openpose 라이브러리를 이용해서 관절 포인트들을 검출해보겠습니다. 한 장의 이미지를 이미 훈련된 pose estimation 모델에 넣어줘서 key point(관절 포인트)들이 검출된 결과를 얻어볼 것입니다
bskyvision.com
https://m.blog.naver.com/rhrkdfus/221531159811
[OpenPose] Python OpenPose 시작하기
* OpenPose : Caffe와 OpenCV를 기반으로 구성된 손, 얼굴 포함 몸의 움직임을 추적해주는 API * ...
blog.naver.com
3) 결과.
저는 아래 이미지를 사용했습니다. 큰 이미지는 결과가 늦게나와 줄여서 사용.

아래와 같이 1)관절검출 2) 스켈레톤 형성 이 순서대로 출력됩니다.


다른 이미지도 한번. 위 이미지 보다 좀더 잘 잡혔다.


* OpenPose? 공부해보기.
- 신체의 특징점(관절) 추론 후 이 관절들을 이어주는 방식으로 되어 있다.
- Whole-Body 2D Pose Estimation(Body, Face, Foot and Hand)을 추출할 수 있다.
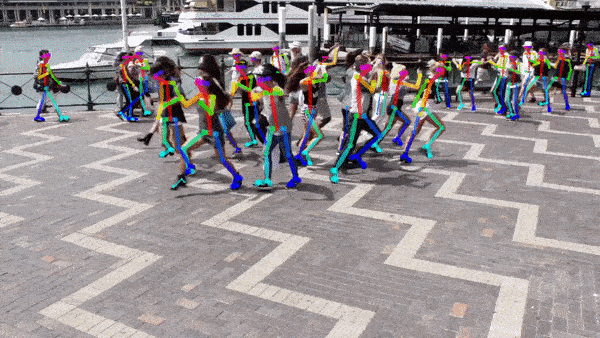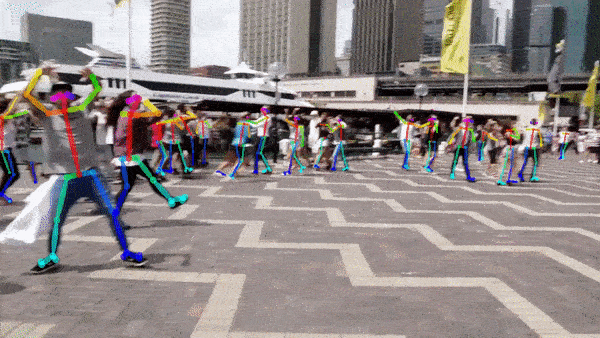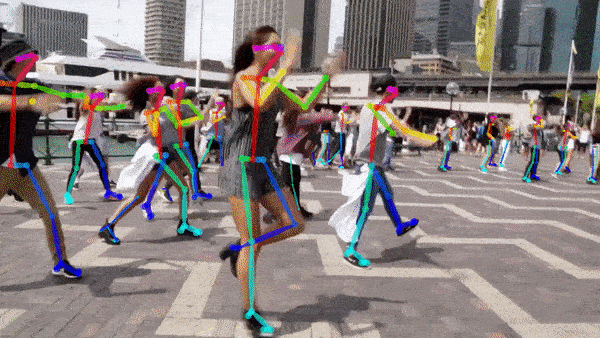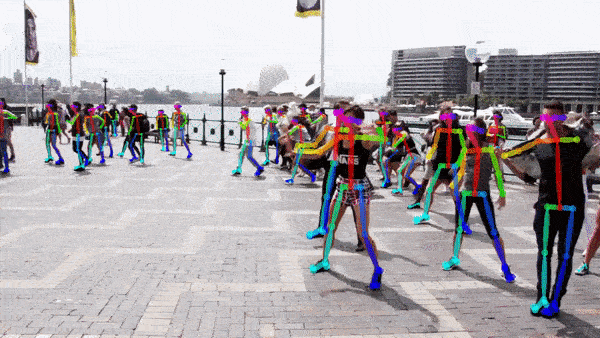


CNN(Convolutional Nural Network)는 BODY-25, COCO, MPII 3가지 모델이 제공된다
1) BODY-25 : 출력 관절이 25개 (COCO와 다르게 골반과 발이 추가 됐다.)
2) COCO : 출력 관절이 18개(https://cocodataset.org/#keypoints-2018)
3) MPII : 출력 관절이 15개( 위 이미지) (http://human-pose.mpi-inf.mpg.de/)
CNN?
이미지를 인식하기 위해 패턴을 찾는데 특히 유용하다. 데이터에서 직접 학습하고 패턴을 사용해 이미지를 분류한다. 전체 이미지를 보는 것이 아닌 부분을 보고 특징을 찾는다.

1) 앵무새의 얼굴 모양, 색, 특징의 패턴을 Convolution으로 가져온다.
2) Convolution-ReLU-Max Pooling을 통해 갈수록 디테일하게 특징을 뽑아 거쳐가는 과정을 CNN이라고 볼 수 있다.
3) CNN에서의 패턴(특징)을 가져와 Fully Connected Layer에서 결과를 예측한다.
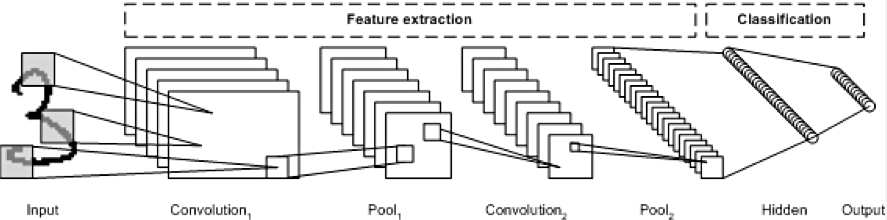
Feature Extraction(특징점 추출)에는 Convolution, ReLU, Max Pooling 이 3가지의 레이어로 층이 쌓여 있다.
CNN 특징점 추출
1) Convoluition Layer : 필터를 통한 이미지 특징 추출
2) Pooling Layer : 특징을 강화시키고 이미지의 크기를 줄임(이를 반복하며 이미지의 특징 추출)
- MaxPooling : 이전 단계에 봅은 특징들에서 일정한 범위를 정하고 수치가 높은 것들만 뽑아서 추출해서 압축
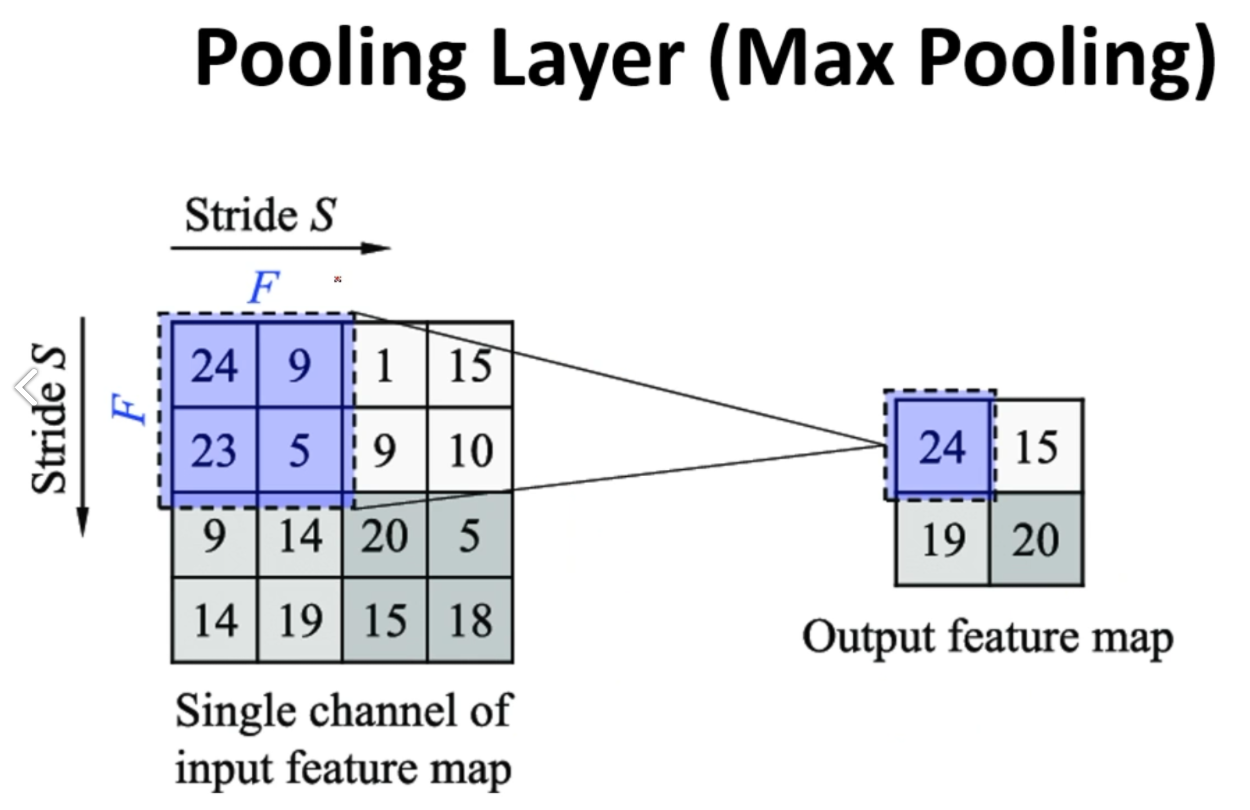
3) ReLU (Activation Function) : 이전 단계에 뽑은 특징(Output feature map)에서 불필요한 요소를 제거한다.
위 3가지 과정을 거치며 중요한 특징을 잡아간다.
Fully Connected로 마지막에 결과를 예측한다.
다시 OpenPose, OpenPose의 딥러닝 네트워크는 VGG-19를 사용하였으며, 이는 다른 네트워크로 변환 가능하다.
VGG-19는 구조가 간단하여 쉽게 변형시킬 수 있어 테스트로 적합한 CNN이다.
VGG-19?

2014년 이미지넷 이미지 인식대회 준우승 모델 VGG-16, VGGNet은 16개 또는 19개 Conv 필터 층으로 구성된 모델이다(VGG16, VGG19). 깊이가 11층, 13층, 16층, 19층으로 깊어지면서 분류 에러가 감소하는 것을 관찰. 즉 깊어질수록 성능이 좋아진다는 것을 확인.
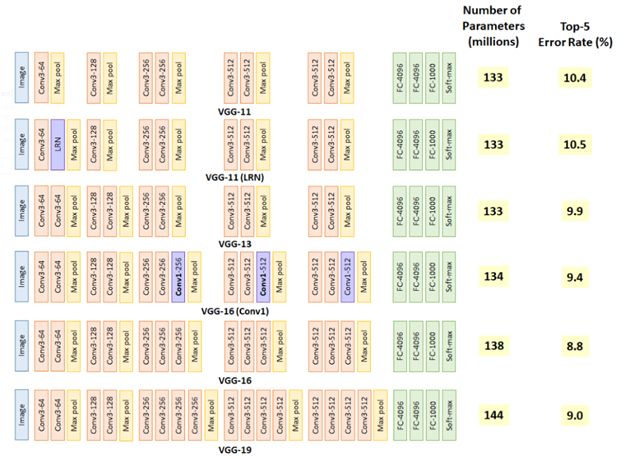
-> CNN 모델 : https://u-n-joe.tistory.com/114
CNN이란?https://hobinjeong.medium.com/cnn-convolutional-neural-network-9f600dd3b395
OpenPose의 Multi-person Pose Estimation model
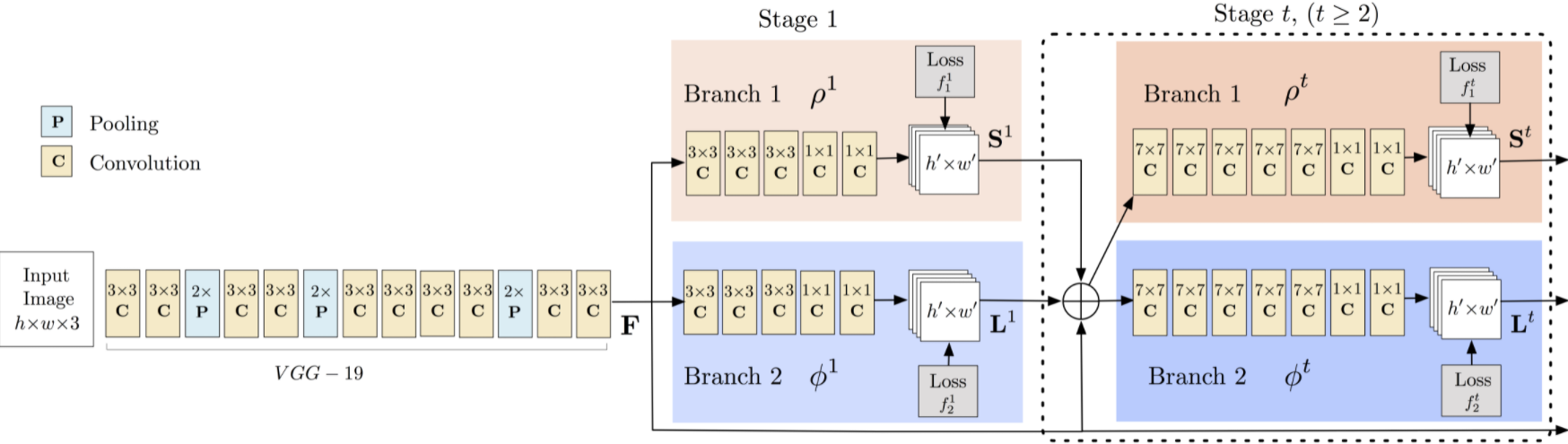
1) VGGNet-19를 통해 Output데이터의 특징을 강조하여 출력
2) 신체의 특정 부위 검출(팔꿈치, 무릎 등)
3) confidence map (인간의 관절 구조 파악), affinity field(관절 주인 파악) 수행.
위의 과정을 반복 학습하여 포즈 완성.
-> https://learnopencv.com/deep-learning-based-human-pose-estimation-using-opencv-cpp-python/
Deep Learning based Human Pose Estimation using OpenCV
Deep Learning based Human Pose Estimation using OpenCV. Tutorial on OpenPose, DNN based pose estimation framework. Python/C++ code is shared for study/practice.
learnopencv.com
오픈포즈(Openpose) 공부했다. 이렇게 쉬울 줄은..
start() { 시작에 앞서 본 포스팅은 아래 순서로 작성 될 예정입니다. 이번 포스트는 1번 'OpenPose' 이론에 해당 합니다. 1. OpenPose 이론 2. OpenPose를 하기 위한 환경 설정 (Ubuntu 기반) 3. OpenPose 작동시..
mickael-k.tistory.com
* OpenPose를 이용한 비디오 인물 포즈 특정
러닝 자세 교정 전 영상에 스켈레톤을 입혀봤다.
코드는 아래 사이트를 참고해서 따라했다.
https://ichi.pro/ko/open-poseleul-sayonghan-kkalkkeumhan-pojeu-chujeong-119999721324518
Open Pose를 사용한 깔끔한 포즈 추정
드디어 여기 있습니다! 역대 가장 기다려온 기사 중 하나이며, 이것이 제가 쓰는 첫 번째 기사입니다! 농담이야. 이것은 단지 지식을 공유하려는 나의 또 다른 괴상한 시도 중 하나입니다.
ichi.pro
from scipy.spatial import distance as dist
import numpy as np
import pandas as pd
import progressbar
import cv2
# 각 파일 path
protoFile = "pose_deploy_linevec_faster_4_stages.prototxt"
weightsFile = "pose_iter_160000.caffemodel"
# 위의 path에 있는 network 불러오기
net = cv2.dnn.readNetFromCaffe(protoFile, weightsFile)
video = cv2.VideoCapture("video.mp4")
n_frames=int(video.get(cv2.CAP_PROP_FRAME_COUNT))
fps=int(video.get(cv2.CAP_PROP_FPS))
ok, frame = video.read()
(frameHeight, frameWidth) = frame.shape[:2]
h=400
w=int((h/frameHeight)*frameWidth)
inHeight=368
inWidth=368
out_path = 'out_11.mp4'
# Define the output
output = cv2.VideoWriter(out_path, 0, fps, (w, h))
fourcc = cv2.VideoWriter_fourcc(*'MP4V')
writer = None
(f_h, f_w) = (h, w)
zeros = None
data = []
previous_x, previous_y = [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
# There are 15 points in the skeleton
pairs = [[0,1], # head
[1,2],[1,5], # sholders
[2,3],[3,4],[5,6],[6,7], # arms
[1,14],[14,11],[14,8], # hips
[8,9],[9,10],[11,12],[12,13]] # legs
# probability threshold for prediction of the coordinates
thresh = 0.1
circle_color, line_color = (0,255,255), (0,255,0)
# Set up the progressbar
widgets = ["--[INFO]-- Analyzing Video: ", progressbar.Percentage(), " ",
progressbar.Bar(), " ", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval = n_frames,
widgets=widgets).start()
p = 0
# Start the iteration
while True:
ok, frame = video.read()
if ok != True:
break
frame = cv2.resize(frame, (w, h), cv2.INTER_AREA)
frame_copy = np.copy(frame)
# Input the frame into the model
inpBlob = cv2.dnn.blobFromImage(frame_copy, 1.0 / 255, (inWidth, inHeight), (0, 0, 0), swapRB=False, crop=False)
net.setInput(inpBlob)
output = net.forward()
H = output.shape[2]
W = output.shape[3]
points = []
x_data, y_data = [], []
# Iterate through the returned output and store the data
for i in range(15):
probMap = output[0, i, :, :]
minVal, prob, minLoc, point = cv2.minMaxLoc(probMap)
x = (w * point[0]) / W
y = (h * point[1]) / H
if prob > thresh:
points.append((int(x), int(y)))
x_data.append(x)
y_data.append(y)
else :
points.append((0, 0))
x_data.append(previous_x[i])
y_data.append(previous_y[i])
for i in range(len(points)):
cv2.circle(frame_copy, (points[i][0], points[i][1]), 2, circle_color, -1)
for pair in pairs:
partA = pair[0]
partB = pair[1]
cv2.line(frame_copy, points[partA], points[partB], line_color, 1, lineType=cv2.LINE_AA)
if writer is None:
writer = cv2.VideoWriter(out_path, fourcc, fps,
(f_w, f_h), True)
zeros = np.zeros((f_h, f_w), dtype="uint8")
writer.write(cv2.resize(frame_copy,(f_w, f_h)))
cv2.imshow('frame' ,frame_copy)
data.append(x_data + y_data)
previous_x, previous_y = x_data, y_data
p += 1
pbar.update(p)
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break
csv_path = 'out_11.csv'
# Save the output data from the video in CSV format
df = pd.DataFrame(data)
df.to_csv(csv_path, index = False)
print('save complete')
pbar.finish()
video.release()
cv2.destroyAllWindows()좀더 코드를 이해한다면 운동시 팔이나 다리 위치, 기울기 등을 수치화해서 볼 수 있을 것 같다. 심심할 때 해보자.
'Software Development > Python' 카테고리의 다른 글
| 파이썬 구글스토어 분석 & 명사 추출 및 시각화 (0) | 2022.10.02 |
|---|---|
| python 두번째 게임 - 마인 스위퍼 (0) | 2020.03.28 |
| python 첫번째 게임 cave - 캐릭터 조작 게임로직 (0) | 2020.03.22 |
| python 첫번째 게임 만들기 - cave, python/pygame 기초 코드이해 (0) | 2020.03.21 |
| Python + Pygame 환경구축 (Window10 / VS code) (2) | 2020.03.15 |